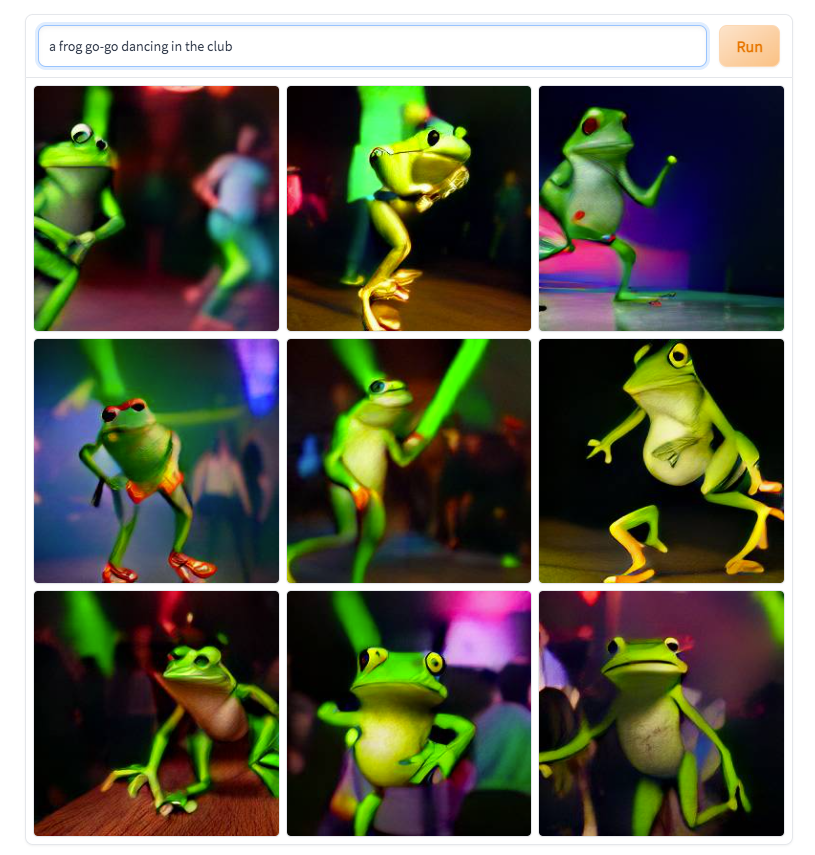
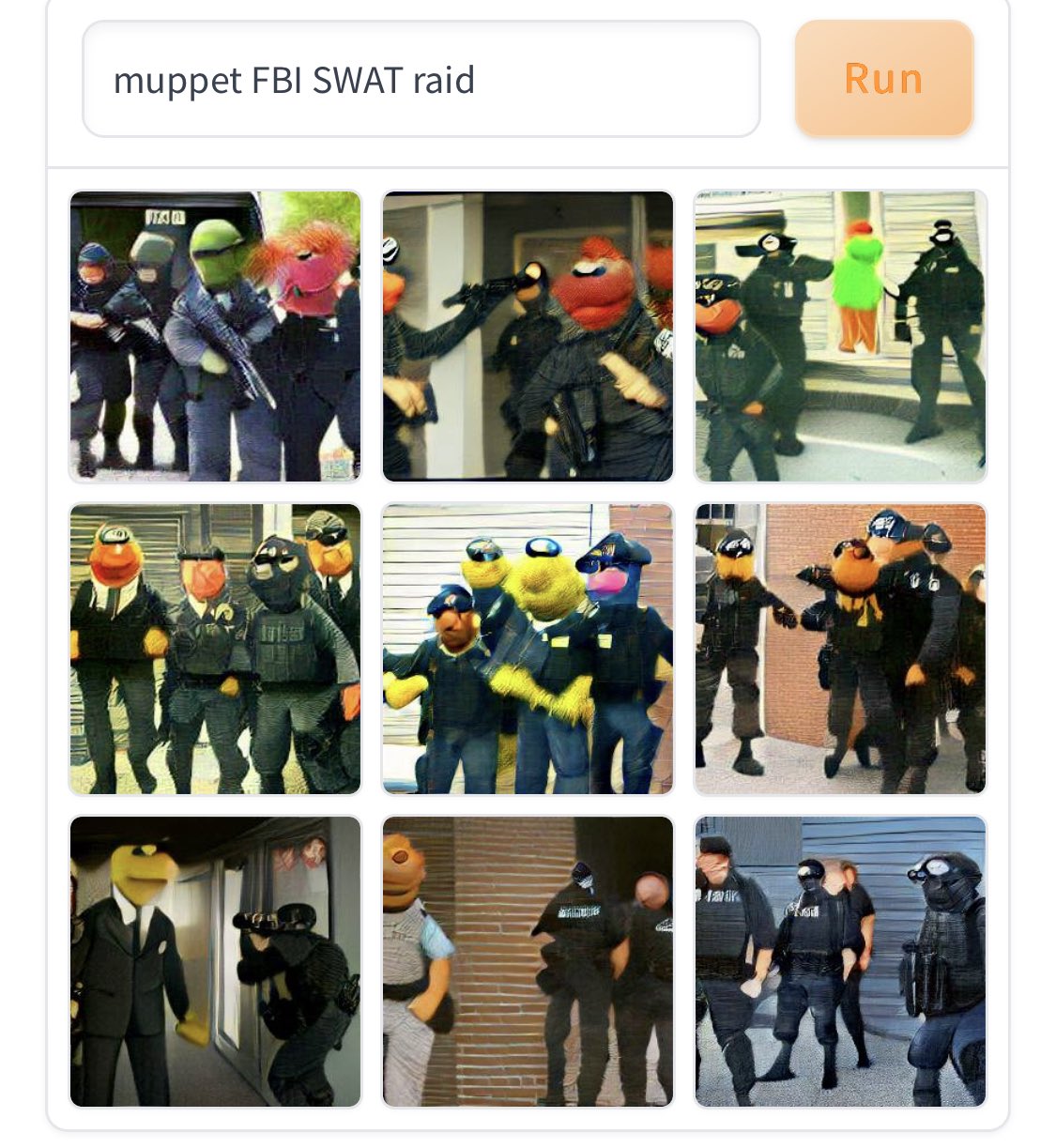
What links an avocado-shaped teapot flying into space, a frog go-go dancing, and an FBI SWAT raid carried out by none other than the Muppets? The clue to the connection between these seemingly disparate, increasingly absurd images, which have all recently have appeared on social media and blogs, lies in an AI system named DALL·E.
A portmanteau of the surrealist artist Salvador Dali and the titular robot WALL-E from the 2008 Pixar film, DALL·E, is an algorithm that can create images based on text descriptions input by online users. Want to see a radish hugging a cucumber? You only have to type the command into the system and away you go. The experience it is not unlike using a deranged search engine: type just about anything you can imagine into it and the image results will appear, no matter how seemingly insane or impossible your request.
Created by OpenAI, a San Francisco-based research laboratory with a billion dollars in funding from Microsoft, the first iteration of DALL·E launched in January 2021. The system makes use of GPT-3 an autoregressive language model that employs deep learning to interpret language-based prompts and generate realistic images in response. Anything from a handbag shaped like a cat to a baseball game on the moon can be created in a matter of seconds.
A team of seven researchers spent two years developing the technology. Like a young child, DALL E needed to be taught the ways of the world in painstaking detail before it could work. Its technology mimics that of a network of neutrons in the brain, learning skills by analysing large amounts of data. DALL·E is able to spot patterns by looking at hundreds of thousands of images of the same object, then recognising the links between images and words. The system had to be trained with millions of images and text pairings before it could be used.
“Type anything you can imagine into it and the image results will appear, no matter how seemingly insane or impossible”
It was with the updated release of DALL·E 2 in April 2022 that the world began to sit up and really pay attention. The images it created were hyperrealistic, with their exacting detail even approaching the unsettling realism of deep fakes. Users were also given the option of introducing further edits to their generated images for the first time.
The eventual ambition of OpenAI is to encourage professional illustrators, artists and designers to make use of this technology when generating new ideas and compositions. Facing a creative block? The solution might lie in a spot of machine learning. Not sure how to realise a brief from a client? Type it into a blank DALL·E page and find your inspiration.
In recent weeks, though, an even newer iteration of DALL·E has made waves on the internet: the DALL·E Mini, created by a company named Hugging Face. OpenAI’s original software is currently available only for researchers to use (and the waitlist to do so is very long), but DALL·E Mini is already open for anyone to use.
There is a caveat: while DALL·E was trained on 400 million pairs of images and text, DALL·E Mini was trained on just 12 million. Inevitably, the results are somewhat less realistic than DALL·E’s. Yet it is precisely this roughness that has led to some unexpected hilarity, helping to make the system something of a breakout online star.
“Anything from a handbag shaped like a cat to a baseball game on the moon can be created in a matter of seconds”
Images created in the system have quickly gone viral. The more convoluted and downright stupid the commands that are entered, the better the result seemingly. These text prompts reveal the contemporary moods of the online public, as they shift in real time in response to various public holidays, pop cultural references and current affairs.
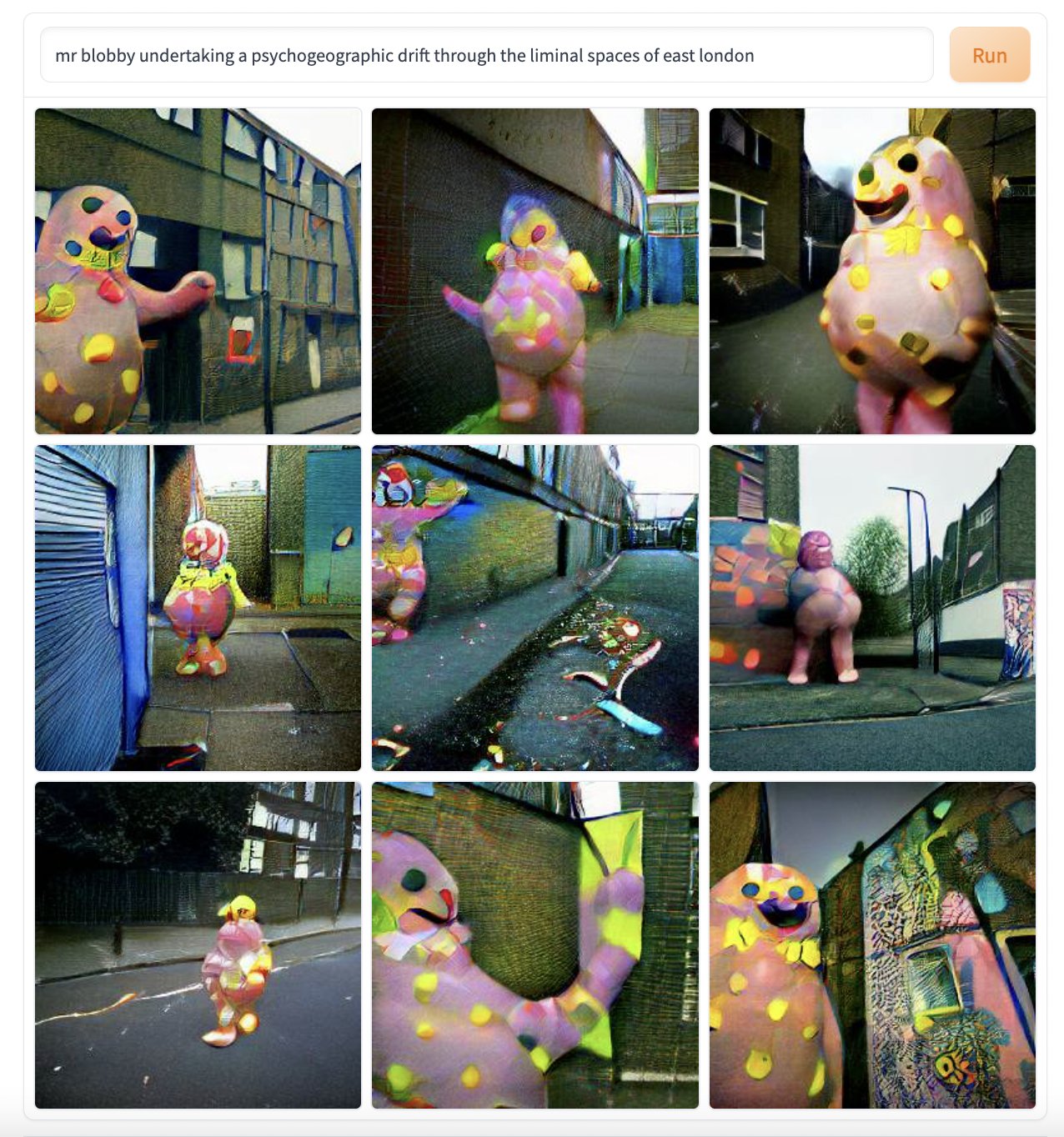
It was unsurprising on the weekend of the Queen’s Jubilee in the United Kingdom that DALL·E Mini was called upon to create images of Elizabeth II, variously attending a criminal court, eating a banana and aiming a rifle. Prime Minister Boris Johnson was put in a fridge ahead of a vote of no-confidence, while Mr Blobby (British television icon of the 1990s) was instructed to undertake a ‘psychogeographic drift’ through the liminal spaces of East London.

Any image-based system faces potential problems of bias and subjectivity though. Image Atlas, a project created by Taryn Simon and the late programmer and internet activist Aaron Swartz in 2012, allows users to investigates cultural differences and similarities by searching for the top image results for given search terms across local engines from around the globe. Supposedly neutral prompts such as ‘cat’ or ‘pickle’, let alone subjective options like ‘beautiful woman’ or ‘delicious meal’, can produce wildly varying results, calling into question not only the possibility of a universal visual language, but also the supposed innocence and neutrality of the algorithms upon which search engines rely.
“It will potentially transform not only how we look at visual art but the very meaning of what constitutes creation”
This kind of discrimination will be an inevitable problem for DALL·E, which is trained on enormous pools of online text, images and other data that already contain bias, particularly against women and people of colour. The technology could also be adopted to create highly convincing deep fakes as it develops, which in turn could be used to spread disinformation online.
OpenAI admit the potential dangers of DALL·E, but note that they have already put some safety measures in place, including limiting the ability for DALL·E 2 to generate violent, hate, or adult images by removing the most explicit content from the training data. They also include a watermark on their images to differentiate them from ordinary photographs. Whether other companies follow suit will remain to be seen.
As DALL·E Mini brings this technology into the mainstream, it will undoubtedly change the ways in which we read images, potentially transforming not only how we look at visual art but the very meaning of what constitutes creation. As Marshall McLuhan wrote in The Medium is the Massage, “We become what we behold. We shape our tools and then our tools shape us.”
Louise Benson is Elephant’s deputy editor





